评测详情
评测详情页是分析 AI 模型性能的关键界面,重点关注模型输出与预期 SQL 的差异。
1. 评测详情界面
评测详情页展示了本次任务的整体成功率(如:50%),以及所有用例的结果。
2. 失败用例分析 (未命中)
对于评测失败(如:"卖的最好的 10 个商品是哪些?")的用例:
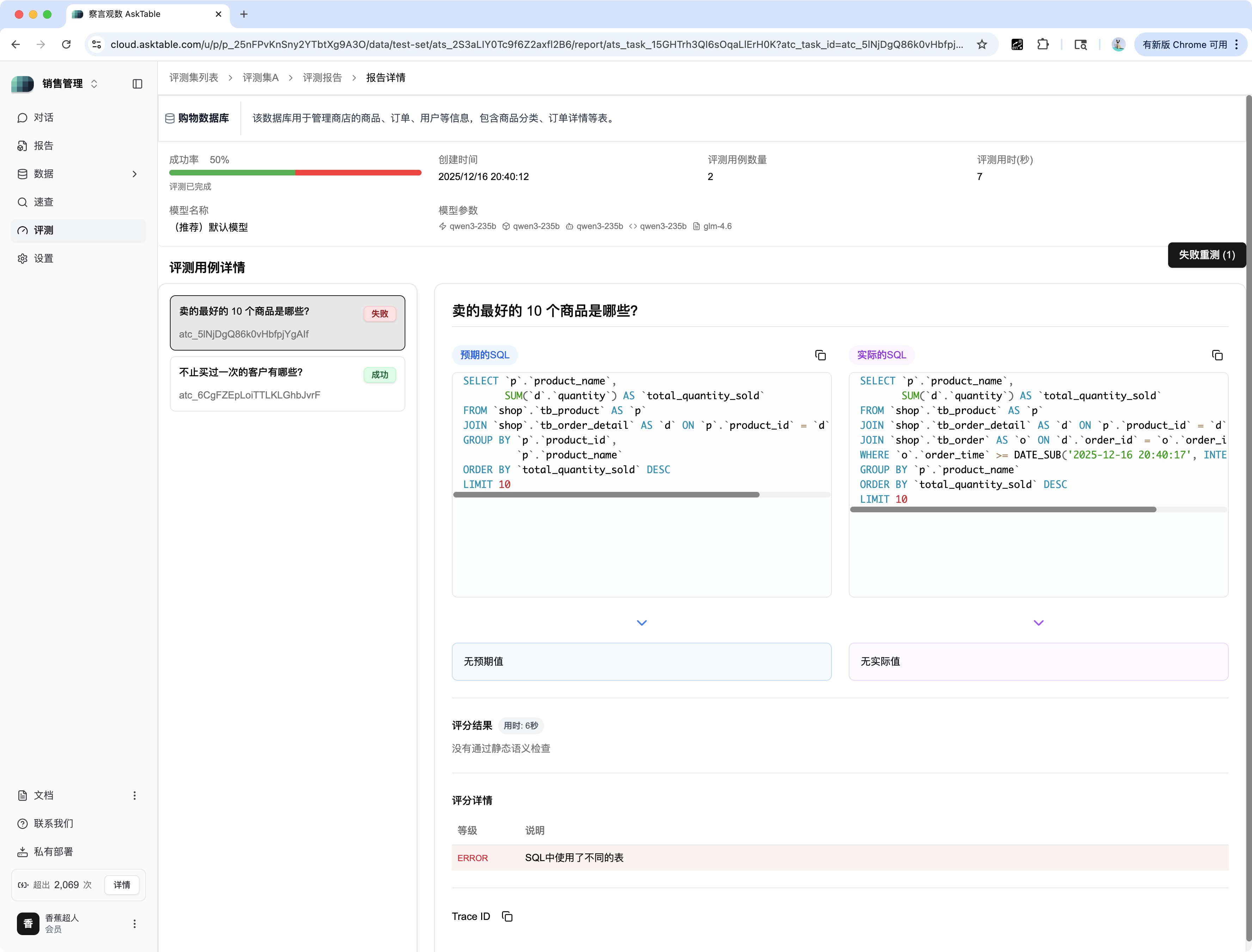
| 区域 | 描述 | 示例分析 |
|---|---|---|
| 用例状态 | 显示为失败(红色标签)。 | 失败 |
| 预期 SQL | 您设定的标准正确 SQL。 | SELECT p.product_name, SUM('d.quantity') ... |
| 实际的 SQL | AI 模型根据问题生成的 SQL。 | SELECT p.product_name, SUM('d.quantity') ...(与预期 SQL 有差异) |
| 评估结论 | 系统对失败原因的总结。 | ERROR: SQL中使用了不用的表/字段 |
| 评估详情 | 提供更详细的错误分析和原因。 | SQL 语句中引用的表名或字段名可能存在错误。 |
3. 成功用例分析 (命中)
对于评测成功(如:"不止关注一次的客户有哪些?")的用例:
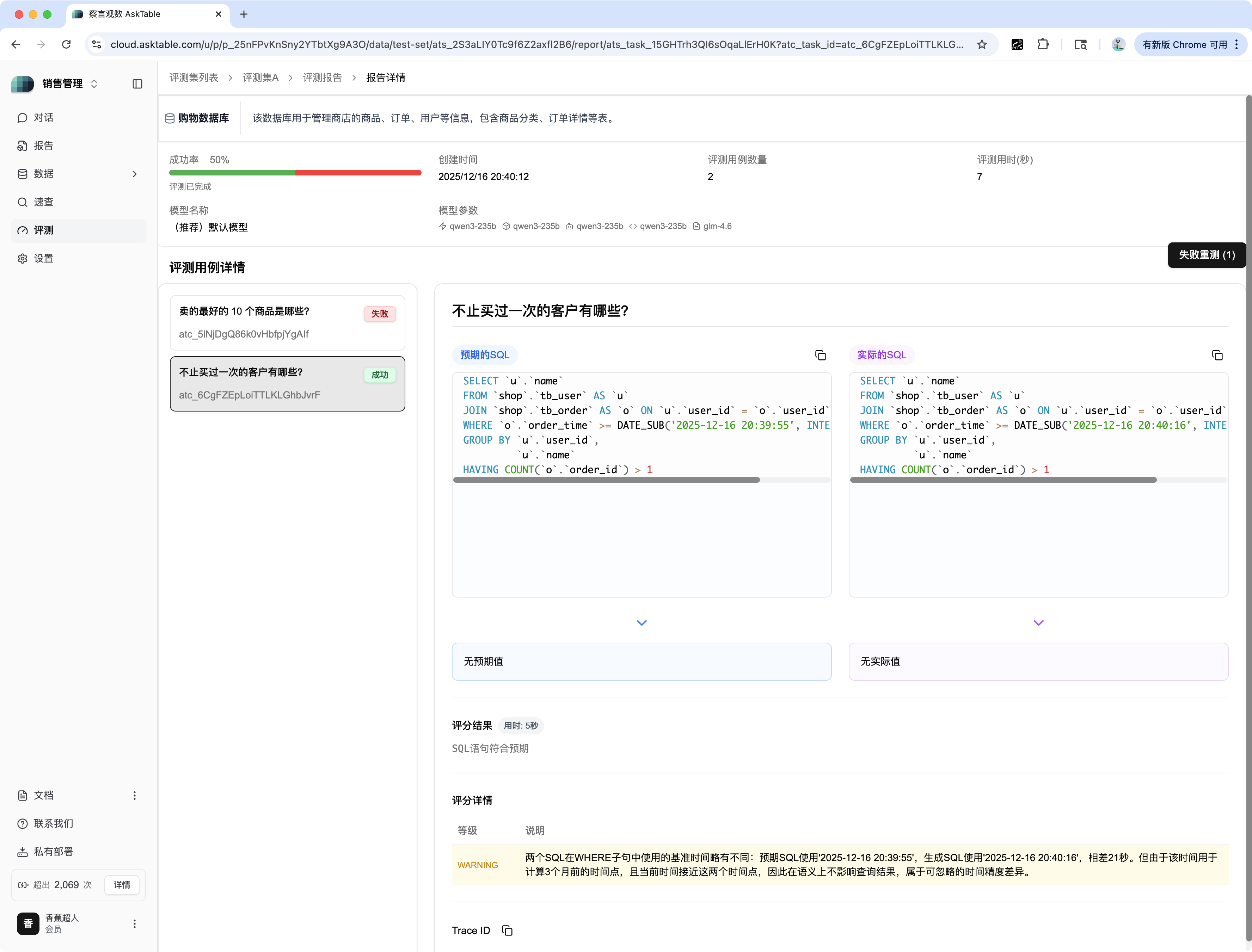
| 区域 | 描述 | 示例分析 |
|---|---|---|
| 用例状态 | 显示为命中(绿色标签)。 | 命中 |
| 评估结论 | 通常显示为无知错误/无事实错误。 | 无知错误 |
| 警告 (WARNING) | 即使结果正确,系统也可能提示潜在的风险或差异。 | WARNING:SQL 语句在 WHERE 子句中使用的日期有所不同,可能导致结果存在微小差异。 |
4. 模型改进
通过分析失败用例的 "评估结论" 和 "预期 SQL" 与 "实际的 SQL" 的差异,您可以精准定位 AI 模型在 表关联、字段引用、时间函数 等方面的缺陷,为模型优化提供数据支持。