AI 评测
一、什么是 AI 评测
AskTable 提供了 AI 评测系统,用于系统化验证大模型在数据分析场景中的表现。该系统确保从自然语言到数据洞察的全流程可靠性。
在此框架下,ATS(AskTable Test Set)作为核心评测数据集,专门设计用于验证 AI 分析能力。ATS 通过预设的评测用例集合,不仅评估 SQL 生成的准确性,还验证从查询到图表展示及数据总结的全流程结果是否符合业务预期。
ATS 实现了标准化的评测机制,帮助企业在发挥大模型价值的同时,有效控制 AI 应用风险,确保分析结果满足实际业务需求。
二、功能概述
AI 评测提供以下核心功能:
-
评测集管理:创建、编辑和删除评测集,对评测用例进行系统化管理。
-
评测用例管理:添加、修改和删除评测用例,灵活配置评测内容。
-
批量评测:支持一次性运行多个评测用例,高效验证模型性能。
-
准确性评估:通过比对生成的 SQL 与预期 SQL 的查询结果,评估大模型对用户问题的理解准确度和SQL生成能力,确保生成的SQL能够正确回答用户的业务问题。
通过 ATS,用户可以在系统升级或模型更新后,快速验证 SQL 生成能力是否符合预期,确保业务查询的准确性和稳定性。
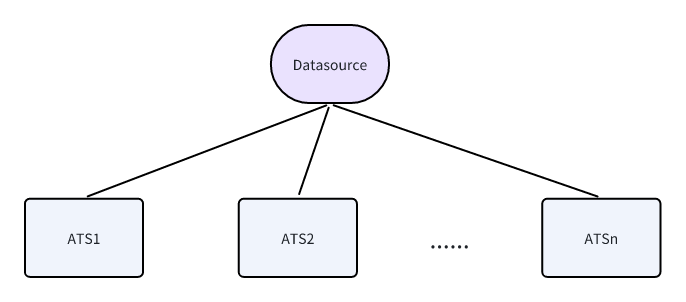
三、ATS和数据(Datasource)的关系
在每个数据(Datasource)上可以创建多个ATS,这种一对多的关系使您能够针对同一数据源创建不同场景或业务领域的多组评测用例,从而全面验证系统在该数据源上的分析能力。
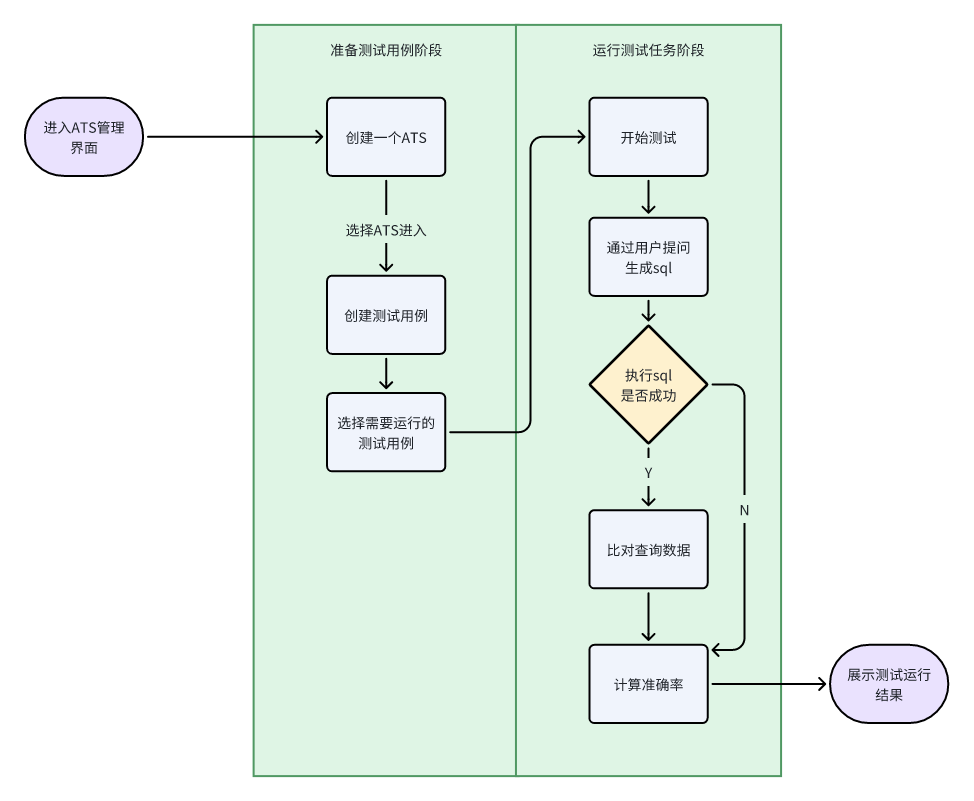
四、评测流程
在每个 ATS 中,用户可以创建多个评测用例(每个 ATS 最多支持 50 个评测用例)。
在评测用例中,用户需填写自然语言问题及对应的预期 SQL。
运行评测任务时,系统会基于评测用例生成 SQL,执行生成的 SQL 和预期 SQL 查询出来的结果进行比对,最终统计并输出评测通过率。
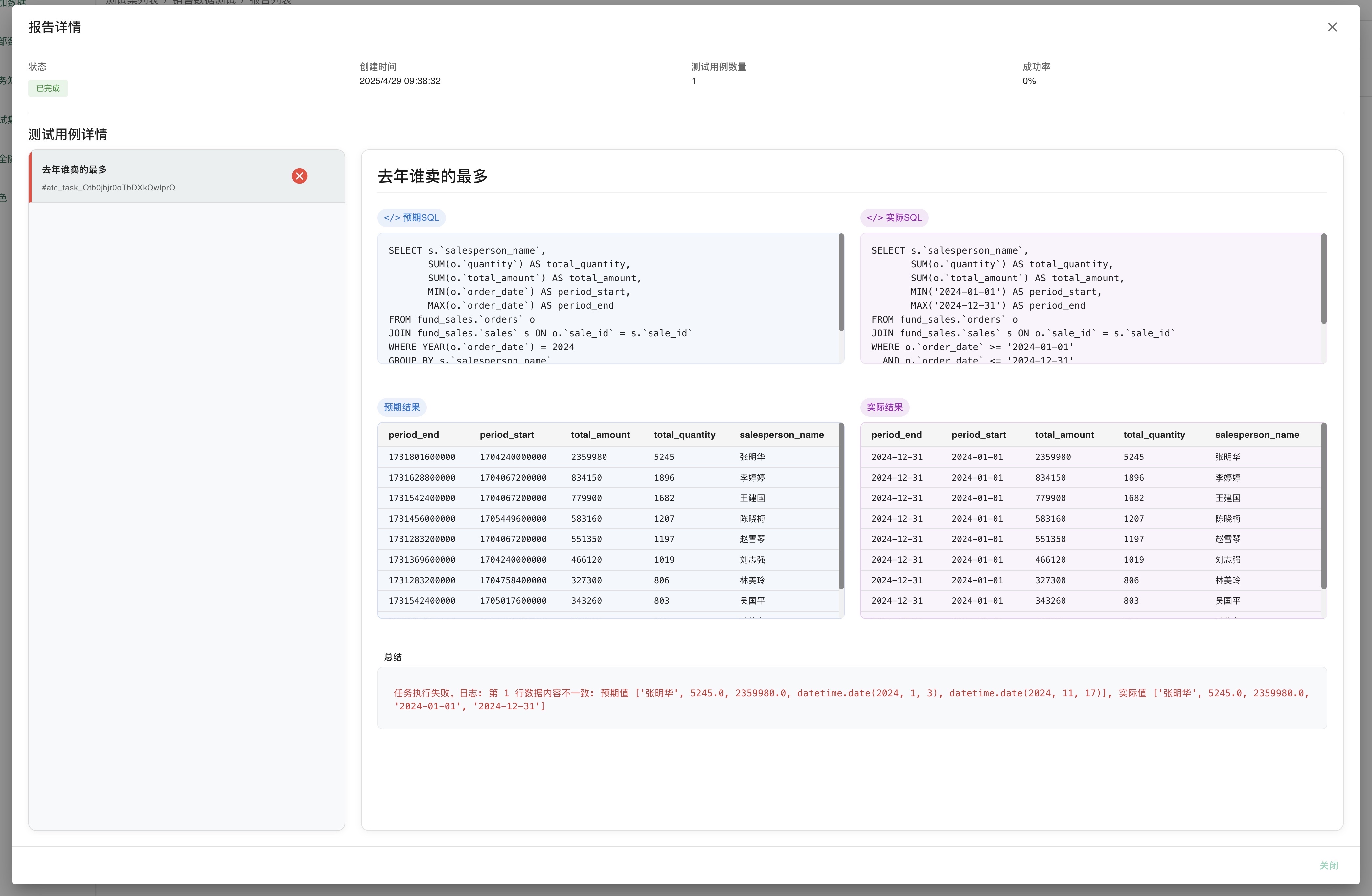
五、常见问题
1. 评测任务如何比对执行结果?
系统通过执行生成的SQL和预期SQL,将两者的查询结果进行对比分析。比对过程具体包括:比对数据行数、列数以及单元格内容是否完全一致。需要注意的是,系统不会比对列名,仅关注数据值的等价性。当所有比对项目均匹配时,评测用例被判定为通过。
2. 评测任务执行时,评测用例是如何运行的?
系统采用并行处理机制,每次同时执行两个评测用例,以提高评测效率。
六、总结
ATS 作为 AskTable 系统中的核心质量保障体系,提供了全流程数据分析准确性的系统化解决方案。通过建立标准化的评测流程,用户可以持续监控和改进系统表现,不仅有效降低SQL生成错误的风险,更能确保图表展示和数据总结的准确性与一致性。随着评测用例库的不断扩充,ATS将持续提升用户从自然语言到数据洞察全链路的可靠性,成为保障AskTable系统稳定高效运行的关键基础设施。